发布时间:March 17, 2023, 6:33 a.m.编辑:李佳生阅读(3273)
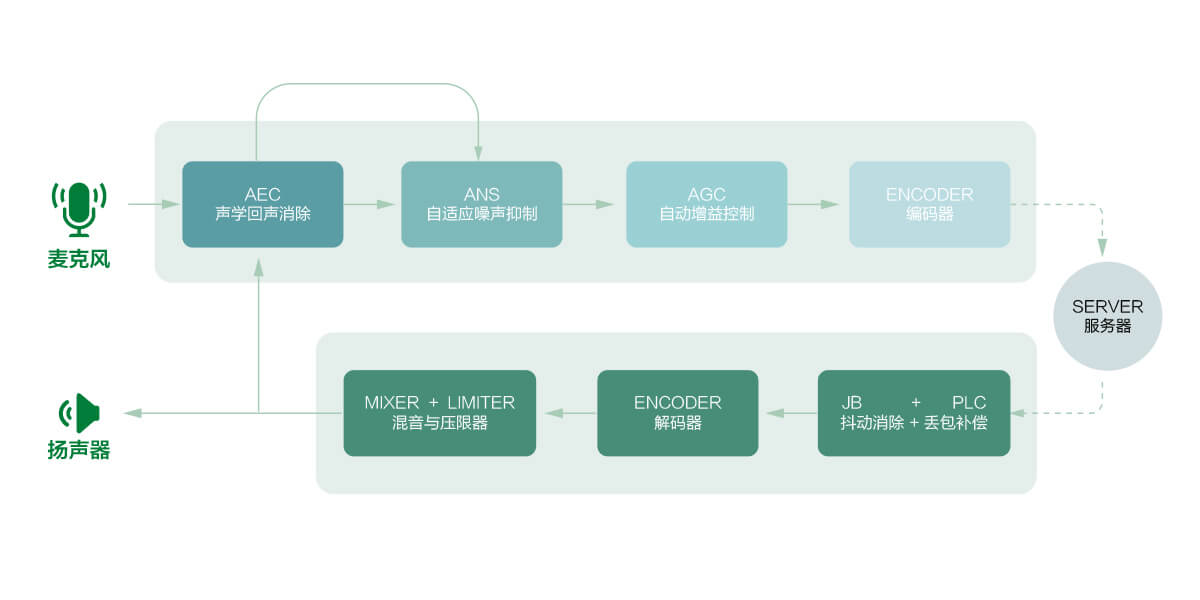
一、AEC回声消除算法
1、背景
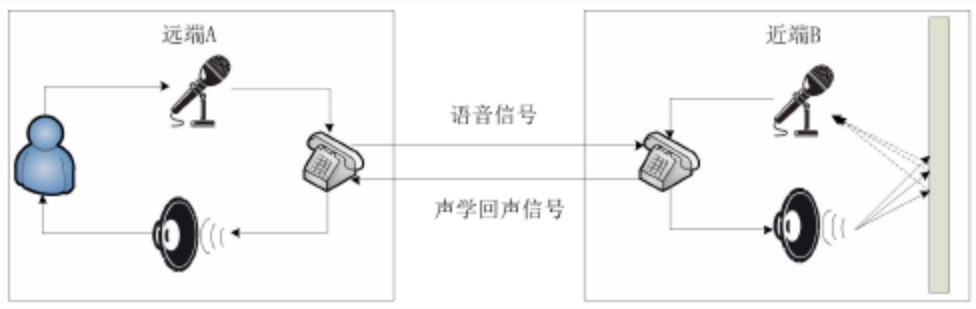
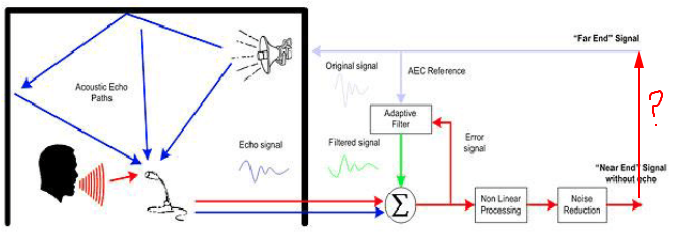
在会议系统、手机通话等场景,经常涉及到大声外放音频的情况。这个外放的声音会被本端的麦克风采集到发送到对端,就形成了我们说的回声(这里只讲声学回声)。无论播放是对端发送过来的语音还是音乐、视频等声音,这些都是只希望本端用户听到而不希望对端用户听到,因此属于不希望采集到的信号,不仅会使发送到对端信号的质量、清晰度下降,当两端或多端设备距离过进时,还会造成啸叫使系统完全不可用。因此需要算法来消除通话中的声学回声,即回声消除算法AEC (Acoustic Echo Cancellation)。
2、原理
通常来说回声消除系统整个的作用流程如下:
(1) 近端接收到远端传来的语音信号
(2) 近端通过扬声器播放远端信号
(3) 扬声器播放的声音经过直接路径传递到麦克的声音以及经过声学环境(如房间反射等等)滤波后传递到麦克的混响,被采集为近端信号
(4) AEC算法通过滤波等方式根据播放的远端信号预测近端信号中的回声成分,并将其从近端信号中减去。理想情况处理后的近端信号不应包括第三步中的任何信号,达到回声消除的目的。
(5) 信号发送给一个或多个远端设备。
因此对回声信号的预测是否准确是回声消除效果的关键,本质也就是对扬声器与麦克之间直接路径和声学环境滤波作用,即回声路径的建模是否准确。传统回声消除算法是通过自适应线性滤波器来对回声路径中的线性部分进行描述,再配合一些非线性部分的处理方法,最终达到一个比较好的效果。现在也有越来越多的人尝试使用神经网络模型来进行回声消除,利用其强大非线性关系的描述能力,在很多场景都可以很好的预测回声信号,提高了算法的能力边界。
3、传统回声消除算法
(1) 自适应滤波器
自适应滤波器是传统AEC算法的重要组成部分之一,其收敛结果的准确性决定了对回声路径的估计是否准确,收敛的准确才能保证回声扣除的干净,不漏回声。另外在算法实际的工作环境中,回声路径往往是不断变化的,因此对算法的收敛速度也有很高要求,需要能够快速响应、跟踪回声路径的变化。
常用于AEC的自适应滤波器方法有LMS、NLMS、SBLMS等:
a) LMS:简单、计算量小;但收敛速度慢,阶数高时容易发散。
b) NLMS:相较于LMS,计算复杂度增加不多,但稳定性好;收敛速度有所加快,但仍不理想
c) SBLMS:拆分子带做LMS,各频带间解耦,单看每个子带更接近于随机白噪声,使LMS收敛速度加快很多,但计算复杂度增加不多。并且各个子带可根据各自频段特点选择收敛帧长、步长等参数,更加灵活。不过子带交叉处容易存在混叠干扰,会稍微影响整体收敛的准确性。
算法详细推导和公式见:自适应滤波
(2) 单讲&双讲检测
单讲分为远端单讲和近端单讲:远端单讲时只有远端信号,但没有近端信号的场景,麦克接收到的信号全部为回声,应尽可能的压制,是滤波器收敛的最佳场景;近端单讲指只有近端信号,没有远端信号,麦克中接收到的信号全部为近端声音,因此应完全停止滤波器的收敛。
双讲指近端和远端同时有信号,麦克接收到的声音中既有远端声音也有近端声音的场景。此时AEC很容易把近端的声音也当成回声消除掉,甚至导致自适应滤波器发散,这不是我们想要的,近端声音应在远端信号消除的同时被保留。因此双讲场景下,回声消除算法需要更加复杂和精确的处理信号,因为两个声音信号之间存在相互干扰和交叉的情况,通常应该减慢甚至停止系数的更新。
所以就需要算法来对双讲的场景进行检测,从而做出相应的处理动作。目前常见的双讲检测(Double-Talk Detection,DTD)算法原理包括但不限于:
a) 能量比较法:基于双讲时d(n)能量显著高于单讲x(n)的假设
b) 相关比较法:基于双讲时d(n)与x(n)相关性低于单讲的假设
c) 基于概率统计的方法:基于阈值后验概率分布的收敛结果进行判断
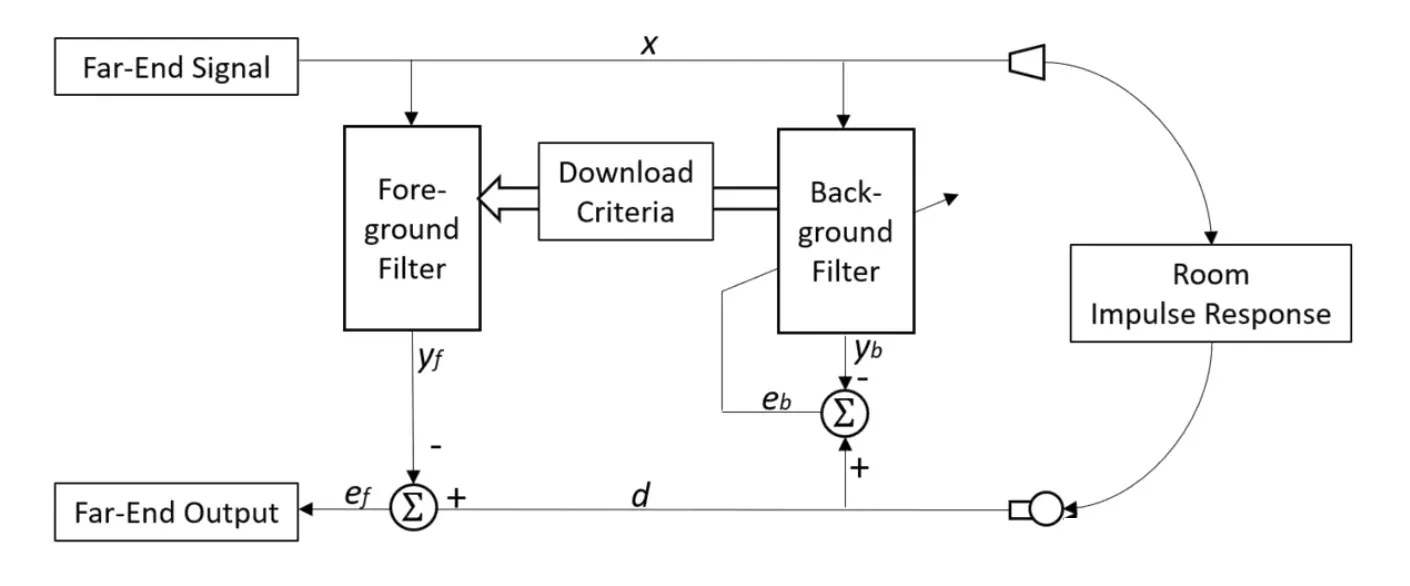
(3) 双滤波器结构
很多AEC算法中会采用双路径结构来提升算法效果和稳定性,这种结构用到了两个滤波器:前景滤波器(foreground filter)和背景滤波器(background filter)。
前景滤波器是当前AEC输出正在使用的滤波器,一般为非自适应的;而背景滤波器通常是一直在持续自适应调整的滤波器。如果经过一定的判断标准,确认背景滤波器的回声消除效果已经好于前景滤波器时,就可将背景滤波器的系统更新到前景滤波器。
背景滤波器可以自由的调整,而不用担心发散而导致实际很差的效果体验,因此可以更好地来跟踪回声路径的变化。即使在双讲等场景下,背景滤波器出现了发散,系统的输出也不会受到任何影响,因为前景滤波器的系数还没有更新。双路径方法为AEC系统的稳定性和效果提供了更强的保障,而且与单路径中的双讲检测方法相比,双路径方法不再严重依赖阈值,一般来说更加灵活且效果更好。
(4) 延时估计
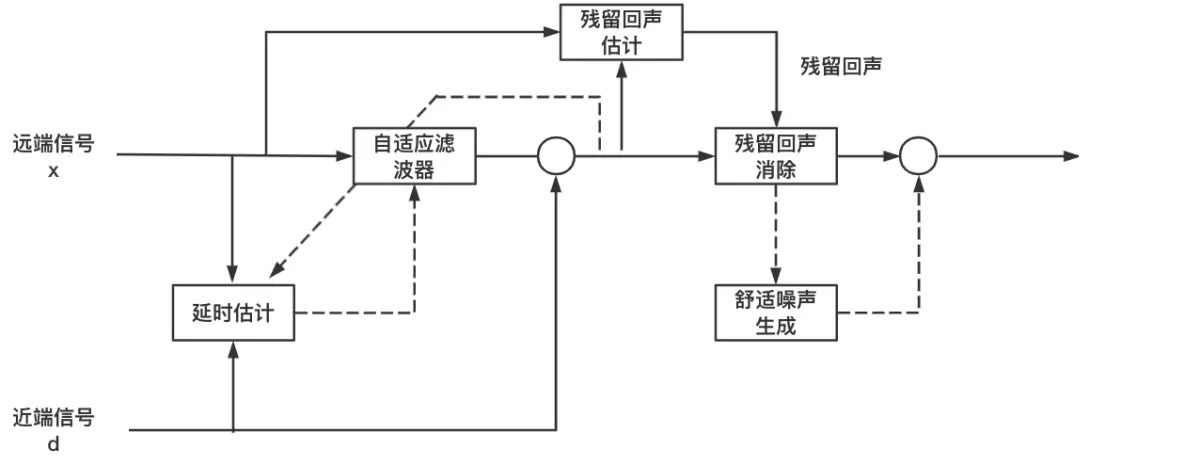
首先需要了解为什么会存在延时:近端信号中的回声是扬声器播放远端信号,又被麦克风采集到的形成的,也就意味着在近端数据还未采集进来之前,远端数据缓冲区中已经躺着n帧参考信号了,这个天然的延时可以约等于音频信号从准备渲染到被麦克风采集到的时间,不同设备这个延时是不等的。比如苹果设备延时较小,基本在 120ms 左右,而Android设备普遍在200ms左右,低端机型上会有300ms左右甚至更大的延迟。
因此延迟可能会导致参考信号先于实际麦克信号传递到AEC算法中,会导致数据没有在时间上对齐。这会使自适应滤波器收敛结果变差,甚至由于存在严重的非因果性,而时滤波器发散。所以需要对延时进行估计,常用的方法有:
(1) 互相关法:参考与麦克信号的互相关函数来估计信号之间的延时,适用于信号的频率带宽较窄的情况。
(2) 相位差法:通过计算信号的相位差来估计信号之间的延时,适用于信号的频率带宽较宽的情况。
(3) 最小二乘法:通过最小化误差平方和来估计信号之间的延时,适用于信号噪声较大的情况。
(4) 卡尔曼滤波法:通过卡尔曼滤波器对延时进行估计,可用于信号噪声较大、信号变化较快的情况。
(5) 均方差法:通过计算信号的均方差来估计信号之间的延时,适用于信号噪声较小、信号变化较缓的情况。
(6) Bastiaan's algorithm:WebRTC中使用的延时估计算法,利用多个子带频域特征来判断,详细介绍见:introduction to WebRTC's AEC
(5) 非线性处理
通过线性自适应滤波器来消除回声,并不能百分之一百把回声消除干净,还需要进一步消除残留的回声。
a) 衰减因子:通常是利用处理后的残留回声与远端参考信号的相关性,来进一步进行残留回声的消除。相关性越大,说明残留回声越多,需要对残留回声进一步消除的程度越大;反之,相关性越小,说明残留回声较少,需要对残留回声进一步消除的程度越小。即根据相关矩阵得到一个反映消除程度的衰减因子,然后将残留回声乘以这个衰减因子,就可以进一步消除残留回声。
另外这个衰减因子通常也跟单讲或双讲状态有关:如果处于远端单讲状态,因为近端没有声音信号(没人说话),需要尽量多地抑制回声,因此可以让衰减因子尽量地小;而如果处于双讲状态,我们则是希望在尽量不损伤近端音质的前提下来消除回声,因此回声的抑制量不会太大,对应的衰减因子也就相对较大
b) 非线性剪切处理:在完成了上述处理以后,其实剩下的回声一般都比较小了,但不排除仍有一些残留的可以感知的小回声。为了进一步消除这些小回声,要根据前面处理得到的衰减量来做进一步的抑制处理。比如为衰减量设定一个很高的保守阈值,如果衰减量达到或者超过设定的阈值,就表明回声消除量比较大,采集进来的语音信号很可能全部都是回声信号,那么就直接将语音信号全部消除掉。
一般能达到那么大的衰减量,基本是处于远端单讲状态或者远端信号要远远大于近端信号的双讲状态。而正常的双讲状态下,为了保护近端语音的音质,不会出现这么大的衰减量。因此只要衰减量达到或超过阈值,把采集到的信号全部消除掉是基本不会影响正常听音效果的。但阈值设置不合理,也会导致近端信号容易被当成回声误杀,需要十分小心。一般有两种做法:一是允许对近端声音有些许损伤也要把远端回声消除干净;另外一种是允许保留些许远端回声也不要对近端声音造成损伤,如果过分消除回声,也可能会造成断续的听音感觉。因此这是一个trade-off问题,算法需要在这两种做法之间找到合适的平衡点。
(6) 舒适噪声
算法在消除回声的同时,可能也会把信号中本身的噪声也消除掉,如果频谱消除的过于干净,会噪声人耳的不适感或信号失真。因此需要使用舒适噪声生成算法CNG(Comfort Noise Generator),通过添加特定的噪声信号来模拟人耳的听觉特性,以改善声音的自然度和舒适度以及降低声音听感的起伏。
基本原理是通过将设计的噪声信号与回声消除处理后的信号进行混合,使得混合信号在听觉上更加自然和舒适。舒适噪声的生成一般与背景噪声相关,算法会根据估计的背景噪声功率生成随机噪声,最后对生成的噪声进行加权。
4、基于神经网络的回声消除算法
传统算法适用于线性稳态的系统和环境,对信号中非线性和非稳态的部分效果比较差,并且线性自适应滤波器在双讲场景效果会变差甚至发散,所以对双讲检测的准确性要求很高,但实际中很容易漏检或误判。因此目前也有很多基于神经网络的回声消除尝试,神经网络有以下优势:
(1) 无需考虑双讲。Double-Talk 是神经网络自己去学习的,因为我们的目标里面隐含Double-Talk 的信息。由于无需检测双讲,避免了传统方法双讲检测不准确时回声消除异常的问题。
(2) 神经网络本身就具有非线性拟合能力,能够更好地覆盖系统中的非线性因素。
(3) 基于数据,无需复杂的调参过程,可以极大地提高工程效率。
(4) 可以将回声消除看做一个分离的问题:麦克信号=回声+近端信号+噪声,有比较成熟的训练方法。
![]() MULTI-CHANNEL AND MULTI-MICROPHONE ACOUSTIC ECHO CANCELLATION.pdf
MULTI-CHANNEL AND MULTI-MICROPHONE ACOUSTIC ECHO CANCELLATION.pdf
![]() JOINT AEC AND BEAMFORMING WITH DOUBLE-TALK DETECTION USING RNN-TRANSFORMER.pdf
JOINT AEC AND BEAMFORMING WITH DOUBLE-TALK DETECTION USING RNN-TRANSFORMER.pdf
![]() Deep Learning for Acoustic Echo Cancellation in Noisy and Double-Talk.pdf
Deep Learning for Acoustic Echo Cancellation in Noisy and Double-Talk.pdf
基于神经网络来进行回声消除具有很大的优势,但是也需要考虑一些制约:数据集的设计比较困难、要求比较高,需要符合真实的回声路径、房间冲击相应,否则实际效果会大打折扣;另外模型的计算开销和模型的大小,在实际工程应用中也受到很大制约,也会使网络的效果退化。因此类似于语音降噪,也可以采取传统AEC和网络结合的方式来进行实际的落地,结合两者的优势来达到效果和开销的综合最优。
常用的模型和数据集在ANS语音降噪算法这篇文章中统一总结。
5、效果评价
回声消除可从几个维度来评价最终效果的好坏:
a) 系统距离DIST:反映了回声消除中自适应滤波器r1(n)对真实回声路径r(n)的逼近程度。
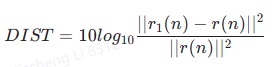
b) 回声返回衰减增益ERLE(Echo Return Loss Enhancement):近端麦克风信号d(n)和回声消除后输出信号e(n)之间的均方log比值。ERLE值越大,则表明回声抵消效果越好,合格的AEC必须不低于6dB。不过双讲或只有近端单讲时,e(n)中包含近端语音,导致大概率e(n)的能量远大于回声y(n)的能量,从而ERLE很小,此时也无法用此指标衡量回声部分的消除情况。
c) 语音质量感知评估PESQ(Perceptual Evaluation of Speech Quality):越大越好,针对双讲(回声信号,和近端信号同时存在)。![]() PESQ.pdf
PESQ.pdf
d) 能量衰减因子SF(Suppression Factor):经过回声消除处理后的信号能量与麦克风信号能量的比值。
e) cohde:输出信号e(n)与麦克风信号d(n)之间的相干性。越接近1,说明保留的麦克风信号越多,回声消除的越少,一般只有近端单讲的情况才能接近1。越接近0,说明输出信号不包含任何近端语音和回声。
f) cohxe:输出信号e(n)与远端信号x(n)之间的相干性,越接近0说明回声消除的越干净。
不同场景下,对各个指标的要求也不一样:
a) 近端单讲:最大程度保持输出与麦克信号一致,因此要求cohde尽量接近1,cohxe接近0,SF接近1。
b) 远端单讲:最大程度抑制回声,因此要求ERLE越大越好,cohde、cohxe和SF尽量接近0,
c) 双讲:尽量抑制回声同时保留近端语音美因茨要求cohxe尽量接近0,SF接近1。cohde需要根据实际情况确定,cohde越接近1说明保留的近端语音频谱成分越多,越接近0说明两者差异越大,一般双讲时理想值为0.5~0.9(取决于回声信号在该帧的占比)。
二、AGC自动增益控制算法
1、背景
在通话、会议、听音乐等采集播放音频信号的场景中,设备差别、下行信号本身的大小、采集声音的大小、距离远近等都会造成信号的能量会随着时间发生改变,把这样的信号播放出来,就会造成实际听感上的忽大忽小;在多人通话时,还可能造成混音后每个远端的音量都不统一。这些情况,不仅会造成听不清或音量过大等不适、体验差的感觉,严重时,甚至还可能会造成听力损伤等情况。
在能量缓慢变化或可预知时,用户可以通过手动调节设备音量来使音量保持在合适的范围内,维持稳定。但音量变化往往很快速且不可预知,用户也不可能一直把注意力放在音量调节上,这时候就需要自动增益控制算法(AGC:Auto Gain Control)来自动调节音量,使其稳定在合适的范围内。优秀的自动增益控制算法能够统一音频音量大小,防止音量过大或爆音,极大地缓解了由信号差异、设备采集差异、说话人音量大小、距离远近等因素导致的最终播放音量差异,是对听感和体验改善十分重要的算法之一。自动增益算法可分为模拟和数字增益控制:模拟增益控制是模拟用户手调设备音量的操作,根据音量对硬件增益进行调节;数字增益控制则是控制音频信号在理想范围内。
2、原理
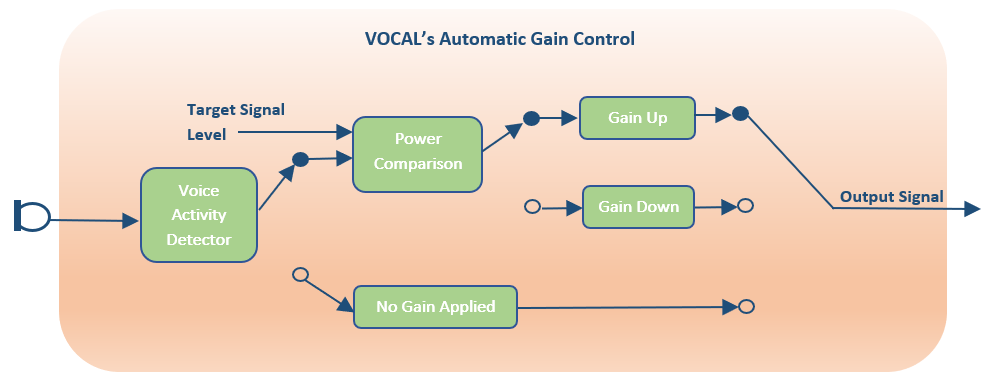
AGC的基本原理十分简单:声音大了就调小,声音小了就调大,但想要做到效果稳定、体验很好,则需要很好的设计和调参。常见的方法是计算语音帧能量期望,根据其与目标能量的离散程度来进行不同的平滑处理调整操作,使其稳定在目标范围内,WebRTC中的AGC模块可以作为一个很好的学习例子: