发布时间:March 17, 2023, 6:35 a.m.编辑:李佳生阅读(3388)
一、背景
在很多语音信号处理算法中,语音和非语音信号是被区分处理的,所以如果算法在有声(说话)和无声(静音)场景采用相同的计算策略,往往会使滤波器的计算和收敛出现误差,造成算法效果变差,所以需要一个模块来区分语音和非语音信号场景,这就是VAD(Voice Activity Detection)语音活性检测算法的主要作用:区分有声(说话)和无声(静音)场景,从而提高算法收敛的效率和准确性。常见的应用场景举例:
1. 语音识别:VAD算法可以帮助识别引擎准确地识别出说话部分,从而提高识别准确率。
2. 语音编解码:VAD算法可以帮助编码器在无声部分停止编码,从而节省带宽和存储空间。
3. 语音通信:VAD算法可以帮助通信系统在无声部分停止传输,从而节省带宽和电力。
4. 语音增强:VAD算法可以帮助增强器在有声部分增强语音信号,而在无声部分不进行增强,进行降噪滤波器的刷新,从而提高最后的增强效果。
因此,VAD算法在语音信号处理中具有重要的作用,不仅可以提高处理效率和准确性,同时也可以节省带宽和存储空间,甚至是保证算法收敛的必要条件。
二、原理
语音信号和环境噪声一般存在较大区别,环境噪声一般为稳态、分布均匀、能量较小的信号,而语音则为能量高、频段特征明显、短时性强的信号。这些区别一般体现在信号的时频域特征上,因此VAD可以根据信号大的这些特征来判断,需要根据实际应用场景来选择合适有效的特征,一般也会通过多个特征的组合来进行综合判断,增加准确率。
三、特征
音频信号的常用的时域特征包括:过零率、能量波动率、能量峰值等等;常用频域特征包括:基频、谐波、频谱质心、频谱频段特征等等。而用于VAD的常见特征一般有:
(1) 短时能量、过零率:利用信号能量和过零率对语音进行最简单的判断,可在时域判断,计算量很小。虽然语音能量一般远远大于噪声能量,但是实际信号有各种各样的特征,噪声和语音之间的能量关系并非一成不变,信号能量也并不一定是语音引起,因此误判率较高且对信噪比要求较高,可用于开销敏感、准确率要求不高的场景。
(2) 频谱频段特征
(3) 倒谱:通过倒谱来分析信号的能量分布和基频特征,可以将频谱包络和细节分开,从而进行比较详细的分析和判断。但是通常需要信噪比比较高,才能判断的比较准确。
(4) 基频、谐波:语音的能量集中于基频和谐波频段,而噪声的能量在各频段分布比较平均平稳,因此可以通过语音基频及其谐波的能量特征将之与噪声区分开来。通常这种特征在低信噪比下准确率也足够高,并且计算量相对较少,因此在耳机和助听器上有所应用。
![]() ANSI S1.11 1986(ASA 65-1986).pdf
ANSI S1.11 1986(ASA 65-1986).pdf
![]() Low_Computational_Complexity_Pitch_Based_VAD_for_Dynamic_Environment_in_Hearing_Aids.pdf
Low_Computational_Complexity_Pitch_Based_VAD_for_Dynamic_Environment_in_Hearing_Aids.pdf
![]() A Real-Time DSP-Based System for Voice Activity Detection and Background Noise Reduction.pdf
A Real-Time DSP-Based System for Voice Activity Detection and Background Noise Reduction.pdf
(5) 长短时信息:一般情况噪声都是稳态、语音都是非稳态的,因此综合长短时信息特征来看,两者差别明显,可以用来区分两种信号。
![]() Voice activity detection algorithm based on long-term pitch information.pdf
Voice activity detection algorithm based on long-term pitch information.pdf
![]() A Survey and Evaluation of VAD.pdf
A Survey and Evaluation of VAD.pdf
(6) 自相关法:周期信号存在自相关性,语音属于短时稳态,所以在一定时间内是存在自相关性的;而噪声一般认为是完全随机的,前后不存在自相关性。因此可以利用这个区别来判断语音信号。
(7) 谱熵:谱熵是一个描述能量谱平坦程度的变量。实验中发现语音的熵和噪声的熵存在较大的差异,能体现语音和噪声在整个信号段中的分布概率,因此出现了基于熵的语音端点检测算法。
假设谱能量为:
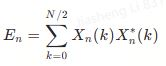
归一化谱能量密度为:
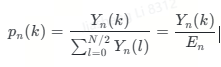
则谱熵的计算公式为:
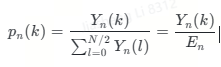
(8) 其他:还有一些其他特征能够反映出频谱能量分布和平稳程度的变化,可以用于区分语音和噪声,如谱差、谱质心等等。
四、判决
有了特征,就可以选择其中一个或多个来进行判决。目前VAD中的判决方法主要分为:
(1) 基于阈值:根据实际系统和工作环境来设定各个特征的判断阈值。
(2) 基于概率模型的统计方法:建立噪声&语音的概率模型(比如GMM),通过概率来判断当前属于哪一种信号,并不断通过梯度或EM算法刷新概率模型参数,使判断越来越准确,比如经典的WebRTC VAD)
(3) 基于机器学习:通过大量特征数据来训练机器学习模型,总结描述出各种特征分布所对应的信号种类,是一种比较暴力的方法,比如经典的语音降噪算法RNNoise就可以顺带输出vad标志位。另外也可以针对想要使用的特征,设计训练专门用于vad的网络,可以做到开销比较小但准确,已很多地用于实际产品中。